Abstract
Entre
les dictionnaires électroniques simples comme le TLFi
(Trésor de la Langue Française informatisé)[1] et les réseaux lexicaux comme WordNet[2] (Diller et al., 1990) (Vossen, 1998), les bases lexicales se développent à grande
vitesse. Notre travail concerne l’ajout de liens riches dans les bases
lexicales, dans le contexte évolutif des réseaux lexicaux. Les recherches actuelles
sur les outils de gestion des bases lexicales sont fortement influencées par le
domaine des données massives (« big data ») et par le
Web des données (« linked data »). Dans le monde des
réseaux lexicaux, on peut construire et utiliser des liens arbitraires mais
les requêtes possibles ne peuvent pas modéliser toutes les interactions
nouvelles avec les développeurs lexicographes et les utilisateurs nécessaires
et issues du monde du papier. Nos travaux ont pour but de trouver une solution qui permet de
bénéficier des avantages principes des réseaux lexicaux et tout en offrant l’équivalent
du dictionnaire papier.
1 Introduction
La place grandissante de l’informatique dans toutes les activités humaines étend et élargit les besoins et les usages de toutes les ressources numériques fondamentales dont font partie les ressources lexicales. Ainsi, si les applications valorisant les traitements linguistiques s’appuient sur des représentations de plus en plus abstraites, modélisées pour des exploitations informatiques, il n’en reste pas moins que les modélisations issues de la construction historique des ressources favorisent la compréhension humaine et, de ce fait, l’outillage des études s’intéressant aux humanités.
Dans cette article, nous replaçons l’émergence de la notion de base lexicale
entre les dictionnaires électroniques et les réseaux lexicaux, nous montrons
que ce concept est toujours d’actualité, qu’il est toujours nécessaire de
l’enrichir, et que nos travaux sur l'amélioration des outils de base lexicale
contribuent à résoudre de réels problèmes scientifiques.
Pour ce faire, nous analysons dans la 2ème section sur l’évolution des ressources lexicales selon 4 étapes principales (dictionnaire électronique simple, base lexicale, base lexicale multi-niveau et multi-version et réseaux lexicaux) et les problématiques. Dans la 3ème section, nous présentons Jibiki-LINKs, une plateforme de construction de bases lexicales multilingues enrichissant la plateforme générique Jibiki par l’introduction du concept de lien riche entre les éléments qu’elle gère (entrées de dictionnaires et volumes de dictionnaires). Enfin, nous montrons qu’elle permet de construire des bases lexicales comme PIVAX-UNL, qui supportent le passage à l’échelle.
2 De la génèse à l’introduction des liens riches dans les bases lexicales
Les premières ressources lexicales informatiques étaient des versions électroniques de dictionnaires imprimés, principalement monolingues ou bilingues. L’usage de l’outil informatique a permis de s’abstraire des contraintes du papier. Le défaut d’inversibilité des dictionnaires bilingues a conduit à modéliser un pivot appelé axie (pour « acception interlingue » par analogue avec « lexie »). Les bases lexicales à pivot sont inversibles et transitives, mais ancrées sur la forme des symboles, alors que les réseaux lexicaux permettent de tendre vers une manipulation sémantique directe des lexèmes indépendamment de leur forme de surface, et ainsi de la langue.
Dans cette section, nous présentons l’évolution historique à travers les quatre types principaux de ressource lexicale et les limitations qui ont motivé leur évolution, ainsi que les problèmes durs restants.
2.1
Dictionnaire
électronique simple
Un dictionnaire électronique simple est une version électronique d’un dictionnaire imprimé ou l’utilisation d’une représentation de même type pour un dictionnaire, par exemple, le TLFi, les dictionnaires morphologiques et bilingues d’Apertium, etc. Un dictionnaire électronique simple contient soit un volume, soit deux volumes.
La version électronique d’un dictionnaire papier monolingue s’appuie sur l’explicitation de sa microstructure, c’est-à-dire de l’organisation de ses entrées sous la forme d’une petite arborescence organisant les informations qu’elle contient.
Dans l’absolu, il est toujours possible de représenter les informations spécifiées dans chaque entrée d’un dictionnaire selon une structure commune. Dans les faits, les dictionnaires conçus dans l’approche papier sont moins rigoureux que ce qu’il faudrait et le traitement automatique oblige à des retouches manuelles.
Un dictionnaire papier bilingue s’appuie généralement sur une structure en deux volumes : un pour chaque couple de langues, chacun des volumes respectant la même microstructure. Il y a généralement un volume de langue A (Lg A) vers langue B (Lg B) et un volume miroir de Lg B vers Lg A. Nous définissions la macrostructure d’un dictionnaire comme l'organisation des volumes qui composent sa structure. Ces macrostructures constituent l'essentiel des dictionnaires imprimés.
2.2
Bases
lexicales
Une base lexicale est un outil d’unification des entrées de dictionnaires, chaque dictionnaire pouvant être monolingue, bilingue, multilingue ou multilingue à structure pivot. Les dictionnaires ont ses macro/micro-structures. Les liens entre les entrées sont matérialisés informatiquement comme des liens directs ou par 2 liens passant par une langue intermédiaire, ou par liens sémantiques etc.
Le défaut de symétrie de la relation entre les entrées des dictionnaires bilingues a fait émerger le concept de pivot interlingue. Ainsi, une la macrostructure pivot a été mise au point et utilisée pour la base multilingue Papillon-NADIA (Sérasset et Mangeot, 2001). Dans cette macrostructure, pour chaque langue, il existe un seul volume monolingue. Les « lexies » sont les entrées de ces volumes, elles représentent un sens de mot (lexème ou locution). Pour regrouper les lexies des différentes langues entre elles, il y a un volume pivot au centre. Les entrées du volume pivot sont les « axies » (acceptions interlingues) qui relient les lexies. Les liens sont directs entre le volume monolingue et le volume pivot. C’est la macrostructure la plus simple pour une ressource lexicale multilingue permettant d’extraire des dictionnaires d’usage.
Les concepts d’axie et de structure pivot ont été définis pour le projet Papillon et ensuite repris dans la norme Lexical Markup Framework (Francopoulo et al., 2009).
2.3 Bases multiniveaux et multiversions
C’est une base lexicale avec l’introduction de
niveaux pour regrouper des entrées selon différents points de vue (langue,
version, type de liens, etc.). L’utilisation de structures des données dépend de la gestion des
axèmes et des liens riches. Ce type de base lexicale permet de gérer les
situations plus complexes. Par exemple, il existe une macrostructure à trois niveaux
(lexie, axème, axie) dans Pivax (Nguyen et al., 2007)
et de quatre niveaux (lexie, prolèmexe, proaxie,
axie) dans ProAxie (Zhang et Mangeot, 2013). On va
les décrire de façon plus détaillée dans la section 4.1. Pour chaque langue naturelle,
elles permettent de gérer un ou plusieurs volumes (en cas de multiversions, par exemple).
2.4 Réseaux lexicaux
Un réseau lexical regroupe l’ensemble des mots qui désignent des idées ou des réalités qui renvoient à un même thème ainsi que tous les mots qui, à cause du contexte et de certains aspects de leur signification, évoquent aussi ce thème[3]. Le thème peut éventuellement être très large. Il est tout à fait possible de représenter le vocabulaire complet d’une langue comme, pour le français le réseau JeuxDeMots (Lafourcade et Joubert, 2010) ou le RLF (Réseau Lexical du Français) (Lux-Pogodalla, Polguère 2011).
Les réseaux lexicaux sont représentés traditionnellement sous forme de graphes. Les nœuds représentent les lexèmes d’une ou plusieurs langues, et les liens représentent les relations entre ces lexèmes (traduction, synonymie, etc.). Un réseau lexical peut être monolingue ou multilingue. On peut créer des relations syntaxiques, morphologiques et sémantiques entre les lexèmes.
Même si les réseaux lexicaux ont beaucoup d’avantages, ils ne conviennent pas à tout le monde et à tous les cas d’utilisation. Par exemple, les réseaux lexicaux comme WordNet (Diller et al., 1990) (Vossen, 1998), HowNet (Dong et al., 2010) et MindNet (Dolan et Richardson,1996) (Richardson et al., 1998) ne sont pas visible par ordre alphabétique. Mais on en a besoin pour jouer à des jeux de mots. Dans un réseau lexical, la notion de volume est absente. Nous ne pouvons pas créer une ressource simple quand on étudie une nouvelle langue.
Il existe par exemple le réseau lexical DBNary (Sérasset, 2012), qui est créé basé sur le model Lemon (McCrae et al., 2011). Ce système ne permet pas d’étiqueter les liens. Pour naviguer dans ce système, il faudra rédiger des requêtes en SPARQL, ce qui n’est pas à la portée de tout le monde.
2.5 Conclusion : caractéristiques, limitations et problèmes durs
Les efforts en recherche portent beaucoup aujourd’hui sur les réseaux lexicaux, alors que pourtant les efforts à produire sur les types précédents (pivot, multiniveau) ne sont pas terminés. En particulier, l’import des bases lexicales dans les réseaux lexicaux provoque une “perte d’information”. Une partie des informations portées par les attributs des liens riches, par exemple sur l’historique, l’étymologie ou l’évolution des sens des mots n’est pas systématiquement importée dans les réseaux lexicaux. Ceux-ci ne peuvent donc pas répondre aux besoins des sciences humaines, ni permettre le passage aux “humanités numériques”.
Le réseau lexical est effectivement le type de structure permettant la plus grande liberté de représentation. En effet, nous pouvons créer les entrées et leurs liens que l’on veut. Mais les requêtes possibles ne peuvent pas modéliser toutes les interactions nouvelles avec les développeurs lexicographes et les utilisateurs nécessaires et issues du monde du papier. Elles permettent de représenter toutes les catégories de ressources lexicales, mais l’analogie avec le monde réel est perdue. De ce fait, on perd l’expertise pratique des linguistes lexicographes.
Il faut continuer d’outiller les bases lexicales car c’est sur ces bases que l’on va pouvoir transférer les techniques exploitées par les linguistes lexicographes. D’autre part, la modélisation par une macrostructure en « volumes » permet de garder un lien originel vers le monde du papier. De plus, il existe déjà des ressources de ces types à réutiliser. C’est pourquoi, dans la suite de cet article, nous nous concentrons sur la gestion des ressources avec des macrostructures multiniveau et multiversion.
3 Réalisation des liens riches
Dans cette section, nous présentons une amélioration qui peut être faite pour les bases lexicales. Elle permet d’introduire dans les bases lexicales de nouvelles informations qui vont les rapprocher des réseaux lexicaux. Il s’agit de la possibilité de créer les liens que l’on veut dans les bases lexicales.
3.1 Présentation de la plate-forme Jibiki
Jibiki est une plate-forme générique, elle permet la construction de sites Web contributifs dédiés à la construction de bases lexicales multilingues. Cette plate-forme a été développée principalement par Mathieu Mangeot (Mangeot et Chalvin, 2006) et Gilles Sérasset (Sérasset et Mangeot, 2001). Elle a été utilisée dans divers projets (projet LexALP, projet Papillon, projet GDEF, etc.). Le code est disponible en source ouvert et téléchargeable gratuitement par SVN sur ligforge.imag.fr. Avec cette plate-forme, on peut faire des opérations d'import, export, d’édition, de modification et de recherche dans des bases lexicales. On peut aussi gérer les contributions. Jibiki permet de traiter presque toutes les ressources lexicales de type XML en utilisant différentes microstructures et macrostructures.
Dans le monde de Jibiki, les ressources sont modélisées « en volume », on a plus de facilités à réaliser l’équivalent du dictionnaire papier, l’image mentale de la représentation du dictionnaire avec les interactions autorisées par l’électronique. Les usages des dictionnaires dans Jibiki sont également semblables à ceux du dictionnaire papier. Par exemple, nous pouvons consulter par ordre alphabétique, indiquer une langue source ou/et une langue cible, regrouper les lexies en vocables, naviguer dans un volume, etc.
3.2 Common Dictionary Markup classique
La version 1 de Jibiki utilise des pointeurs CDM (Common Dictionary Markup) (Mangeot, 2002) pour importer, afficher et éditer n'importe quel type de microstructure sans la modifier. Les pointeurs sont utilisés également pour indexer des parties d'information spécifiques et permettre ensuite une recherche multicritère. Pour chaque pointeur CDM, on indique le chemin XPath vers l'élément correspondant dans la microstructure XML de la ressource à décrire (voir figure 1). La description des pointeurs est stockée dans un fichier de métadonnées sous forme XML. Puis, lors de l’import de la ressource sur la plate-forme Jibiki, les pointeurs sont calculés et le résultat est stocké dans une table de la base de données (postgresql) pour chaque volume. Cette table est considérée comme une table d’indexation.

Figure
1 : pointeurs CDM pour le volume français de la ressource GDEF (Mangeot et Chalvin, 2006)
Les liens de traduction sont à ce stade traités avec des pointeurs CDM classiques, comme des éléments d'information classiques. Il n’est pas possible d’indexer des informations supplémentaires portées par les liens, telles qu’un poids ou une étiquette.
Les macrostructures multiniveau ne peuvent donc pas être modélisées de manière générique avec Jibiki v1 et les CDM traditionnels. Par exemple, il n’est pas possible d’établir des liens d’un même volume vers plusieurs volumes de niveaux différents. Cela nous a obligés dans un premier temps à utiliser des palliatifs qui ne passaient pas à l’échelle. Il était nécessaire de modifier le modèle conceptuel. Nous avons remédié à ces défauts dans la nouvelle version Jibiki-LINKS.
Ci-dessous la table 1 est un exemple de CDM pour les différentes ressources.
|
Dictionary Pointers |
FeM |
OHD |
JMdict |
|
Volume |
/volume |
/volume |
/JMdict |
|
Entry |
/volume/entry |
/volume/se |
/JMdict/entry |
|
Entry ID |
/volume/entry/@id |
|
/JMdict/entry/ent_seq/text() |
|
Headword |
/volume/entry/headword/text() |
/volume/se/hw/text() |
/JMdict/entry/k_ele/keb/text() |
|
Pron |
/volume/entry/prnc/text() |
/volume/se/pr/ph/text() |
|
|
PoS |
//sense-list/sense/pos-list/text() |
/volume/se/hg/ps/text() |
/JMdict/entry/sense/pos/text() |
|
Domain |
|
//u/text() |
|
|
Example |
//sense1/expl-list/expl/fra |
//le/text() |
/JMdict/entry/sense/gloss/text() |
Table 1 : Exemples de Common Dictionary Markup
3.3 Nouvelle version de Jibiki avec CDM LINKS
Afin de gérer les macrostructures multiniveaux, nous avons enrichi les CDM avec une description plus riches des liens (voir figure 2). Pour chaque lien, plusieurs informations peuvent être indexées :
· l’identifiant de l’entrée source;
· l’identifiant de l’entrée cible;
· l’identifiant de l’élément XML de l’entrée source contenant le lien. Par exemple, le numéro de sens lors d’une entrée polysémique avec un lien de traduction pour chaque sens. Cela permet de retrouver précisément l’origine du lien;
· le nom du lien. Celui-ci est utilisé pour distinguer des liens de types différents dans une même entrée, par exemple un lien de traduction et un lien de synonymie;
· la langue cible (code à trois lettres ISO-639-2/T);
· le volume cible;
· le type de lien. Certains sont prédéfinis car ils sont utilisés par les algorithmes de calcul des liens riches (traduction, axème, axie), mais il est possible d’en utiliser d’autres;
· une étiquette dont le texte est libre;
· un poids dont la valeur doit être un réel.
Ces liens peuvent être établis entre deux entrées d'un même volume ou entre deux volumes différents. Un même volume peut regrouper des entrées reliées à plusieurs volumes.
Pour réaliser l'implémentation de liens riches, nous avons séparé le module de traitement des liens de celui des autres pointeurs CDM.

Figure 2 : CDM-LINKS pour le volume anglais de la ressource CommonUNLDict
3.4 Approche des liens riches dans la recherche complexe comme un réseau lexical
Pour expliquer comme on crée les liens que l’on veut, on montre ici un exemple. Une étiquette libre est disponible pour chaque lien. Par exemple, pour une ressource lexicale comprenant des textos, en français « A+ » correspond à « À plus » avec une étiquette « texto », en anglais « L8R » correspond à « later » avec l'étiquette « texto », et l’étiquette du lien entre « À plus » et « later » est « traduction ». Une macrostructure ProAxie (Zhang et Mangeot, 2013) a été réalisée sur la plate-forme Jibiki-Links. Nous allons présenter un autre exemple de liens riches pour la recherche sémantique dans la section 4.1.
3.5 Algorithmes de calcul des liens riches
La réalisation informatique est basée sur deux algorithmes. Le premier collecte les liens, le deuxième construit le résultat. Plus précisément, le premier recherche tous les liens possibles dans l'ensemble des liens riches de tous les volumes pour une entrée recherchée. Le deuxième réalise récursivement les étapes suivantes : (1) sélection de l'entrée de départ ; (2) recherche des liens vers d'autres entrées; (3) traitement des étiquettes ; (4) appel récursif de l'algorithme sur l'entrée reliée ; (5) intégration du code XML de l'entrée reliée au code de l'entrée de départ ; (6) affichage.
4 Mise à l’épreuve
4.1 Exemples de macrostructures multiniveau
Nous avons déjà installé plusieurs macrostructures multiniveau sur Jibiki-LINKS. Ici, nous donnerons trois exemples.
· MotÀMot : base lexicale trilingue à structure pivot (Mangeot & Touche, 2010)
· ProAxie : extension multilingue de ProxlexBase (Tran, 2006)
La macrostructure ProAxie a pour but de résoudre le problème de la mise en relation de plusieurs termes qui désignent un même et unique référent, en particulier pour la gestion des acronymes (Zhang et Mangeot, 2013). Dans cette macrostructure, il y a deux couches différentes.
Une couche de base comprend deux types de volumes : volumes des lexies et volumes des axies. Les axies permettent de relier les lexies qui se correspondent exactement. Par exemple, on traduit « ONU » par « UN » (voir figure 3).
Une couche « Pro » permet de proposer les traductions de même sens. Cette couche comprend les volumes de prolexèmes (Tran, 2006) et un volume de proaxies. Une entrée de prolexème relie les lexies de même sens avec une étiquette (alias, acronyme, définition etc.). Une entrée de proaxie relie les prolexèmes des langues différents. Quand on ne trouve pas les traductions directement par la couche basse, grâce à la couche « Pro », on trouvera les traductions proposées.
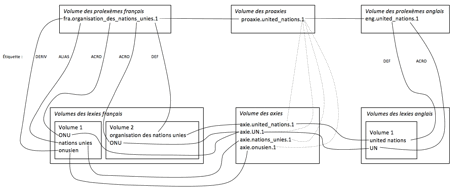
Par
exemple, on propose « Nations Unies » qui est traduit avec une étiquette «
alias » par « United Nations » et « UN ».
Figure 3 : Exemple de ProAxie
Pour chaque langue naturelle, il existe un ou plusieurs volumes de lexies, un seul volume de prolexèmes. Pour chaque dictionnaire, il existe un volume d’axies et un volume de proaxies.
Il y a trois niveaux de traduction classés selon la précision obtenue. Le système trouve une lexie directe par le volume des axies. C'est le premier niveau de traduction et le plus précis. Le système cherche le lien dans le volume des prolexèmes de la langue source avec une étiquette. Puis il trouve le lien dans les proaxies, ensuite il suit le lien de prolexème de langue cible, et enfin il arrive au volume des lexies de la langue cible, et trouve une lexie qui a une même étiquette. C’est le deuxième niveau. Le système trouve les lexies par prolexème et proaxie sans étiquette correspondante. Ces lexies proposées constituent le troisième niveau, le moins précis.
· Pivax : base multilingue multiversion à 3 niveaux
La macrostructure Pivax a trois niveaux : lexie, axème et axie (Nguyen et al., 2007). Les axèmes sont les acceptions monolingues, elles regroupent les lexies monolingues de même sens. Les axies regroupent les axèmes de différentes langues dans un « pivot » central. Dans certaines situations, une base lexicale (un dictionnaire) a plusieurs volumes pour une seule langue. Par exemple, lorsqu'il y a plusieurs versions d'édition ou que la ressource lexicale est créée par un système de traduction automatique, on trouvera un volume provenant de Systran, un provenant de Google, un provenant d'IATE ("A single database for all EU-related terminology (InterActiveTerminology for Europe) in 23 languages opens to the public", 2007), etc. Cette macrostructure permet de gérer plusieurs volumes dans une même langue. Étant donnée une langue, il existe un ou plusieurs volumes de lexies et un seul volume d’axèmes. Pour un dictionnaire, il existe un seul volume d’axie. Les liens entre les lexies et les axèmes et entre les axèmes et les axies sont des liens riches avec des attributs comme type, volume cible, langue cible, étiquette libre, poids etc.
4.2 CommonUNLDict : vers le passage à l’échelle avec une ressource de type Pivax
Dans cette section, nous présentons la ressource CommonUNLDict, qui utilise la macrostructure Pivax. Nous avons implementé cette ressource sur la plate-forme Pivax-UNL qui est une instance de Jibiki-Links. Les utilisateurs peuvent utiliser facilement cette ressource par le lien : http://getalp.imag.fr/pivax/Home.po.
· Ressource créee par les linguistes
Grâce à CDM-LINKS, tous les types de formats XML peuvent être reutilisés dans une instance de Jibiki-LINKS sans modification. On n’a besoin que de connaissances simples du XML pour créer une ressource pour Jibiki-LINKS. En plus, on y a intégré des outils très utiles pour créer un fichier XML, comme oXygen[4], qui permet de créer une DTD en utilisant une interface graphique.
La ressource CommonUNLDict a été créée par le linguiste russe Viacheslav Dikonov (Dikonov et Boguslavsky, 2009).
· Macrostructure de CommonUNLDict
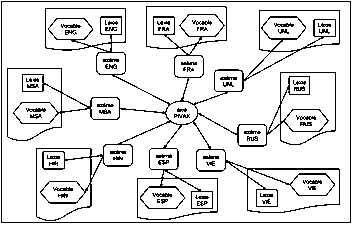
CommonUNLDict
contient 8 langues (7 langues naturelles : français, anglais, hindi, malais, russe,
espagnol, vietnamien et le langage UNL) et 17 volumes (8 volumes de données monolingues,
8 volumes d’axèmes monolingues et 1 volume d’axies « acceptions interlingues »). La macrostructure de CommonUNLDict
est schématisée dans la figure 4. Pour chaque langue, il existe un seul volume
de données monolingues (vocables et lexies) et un seul volume d’axèmes. Pour le
dictionnaire, il existe un seul volume d’axies.
Figure 4 : Macrostructure de CommonUNLDict
· Microstructure de CommonUNLDict
La microstructure est la structure des entrées (Mangeot, 2001). Dans la ressource CommonUNLDict, il y a trois types d’entrées (vocables, axèmes et axies). Elle comprend 720 K entrées au total. Voir la table 2.
|
Volume |
Langue |
Entrées |
|
CommonUNLDict_axi |
axi |
82804 |
|
CommonUNLDict_eng |
anglais |
45471 |
|
CommonUNLDict_eng-axemes |
anglais |
82069 |
|
CommonUNLDict_esp |
espagnol |
7080 |
|
CommonUNLDict_esp-axemes |
espagnol |
22254 |
|
CommonUNLDict_fra |
français |
27537 |
|
CommonUNLDict_fra-axemes |
français |
48312 |
|
CommonUNLDict_hin |
hindi |
31255 |
|
CommonUNLDict_hin-axemes |
hindi |
50380 |
|
CommonUNLDict_msa |
malais |
37342 |
|
CommonUNLDict_msa-axemes |
malais |
31699 |
|
CommonUNLDict_rus |
russe |
28475 |
|
CommonUNLDict_rus-axemes |
russe |
45020 |
|
CommonUNLDict_unl |
unl |
82804 |
|
CommonUNLDict_unl-axemes |
unl |
82804 |
|
CommonUNLDict_vie |
vietnamien |
6585 |
|
CommonUNLDict_vie-axemes |
vietnamien |
8819 |
Table 2 : Nombre des entrées de CommonUNLDict
Tous les volumes d’un même type ont une même microstructure. L’exemple ci-dessous illustre la microstructure d’un volume de vocables (voir figure 5). Chaque entrée de type vocable permet de décrire toutes les informations détaillées comme la partie du discours (POS), la prononciation, etc. Chaque vocable comprend une ou plusieurs lexies (sens de mot). La figure 2 dans la section 3.3 nous montre un exemple. C’est pourquoi le nombre d’axèmes est supérieur ou égal au nombre de vocables. Dans cette microstructure, l’attribut « entryref » permet de gérer les liens entre les lexies et les entrées de type axème.
Dans cette microstructure, l’attribut « entryref » permet de gérer les liens entre les lexies et les entrées d’axème. Dans cet exemple, la value de « type » est le type de lien, la value de « volume » est le volume cible, la value de « idref » est l’identifiant d’entrée d’axème, la value de « lang » est la langue cible et la value de « relation-mono » correspond au l’étiquette.

Figure 5 : Microstructure d’un volume de lexies
La microstructure des entrées de type axème, permet de décrire les liens avec les entrées de type lexie et les liens avec les entrées de type axie. La microstructure des axies permet de décrire les liens avec les entrées de type axème.
· Temps de réponse et exemple d’utilisation
Les tests ont été effectués avec une instance de Jibiki LINKS installée sur une machine équipée d’un processeur Intel Core i3 à 3,3 Ghz avec 8 Go de RAM. L’outil utilisé pour effectuer les requêtes est wget. La commande est lancée directement sur le serveur pour éviter le temps de latence dû au réseau.
Nous donnerons 3 exemples dans la table 3, qui montrons le nombre de liens calculé par le système, les entrées affichées, le nombre de requêtes, les langues différents et le temps moyen de réponse.
Le temps de réponse, inférieur à 1 seconde dans ces cas est globalement satisfaisant.
|
Argument de recherche |
Liens |
Entrées affichées |
Nombre de requêtes |
Langues découvert |
Temps moyen (ms) |
|
Vocable « manger » |
14 |
6 |
10 |
6 |
197 |
|
Vocable « recherche » |
66 |
27 |
10 |
6 |
735 |
|
UNL « search » |
51 |
20 |
10 |
6 |
560 |
Table 3 : Temps de réponse de trois exemples
La figure 6 montres l’affichage de l’interface pour une recherche classique dans un navigateur Web.
Figure 6 : Affichage de l’interface pour une recherche classique
5 Conclusion et perspectives
Dans cet article, nous avons analysé les différents types de ressource lexicale et présentons une méthode de modélisation des ressources lexicales en volume. Cette méthode permet de gérer les ressources complexes et faciliter à réaliser l’équivalent du dictionnaire en papier.
La Jibiki-LINKS est une nouvelle version de la plate-forme Jibiki. Elle peut gérer les ressources en macrostructure multi-niveaux en utilisant les liens riches. La gestion des liens riches correspond aux liens avec des attributs, comme volume cible, poids, type, langue, étiquette libre, etc. Pour réaliser l’implémentation de liens riches, nous avons séparé le module de traitement des liens de celui des autres pointeurs CDM. Grâce à Jibiki-LINKS, nous avons implémenté les macrostructures MotÀMot, ProAxie et Pivax.
La plate-forme Pivax-UNL, une instance de Jibiki-LINKS pour la macrostructure Pivax, nous avons installé les ressources CommonUNLDict de Dikonov dans cette plate-forme. On a testé notre plate-forme avec cette ressource.
Il existe aussi une ressource d’UNL de 8G qui est récupéré à partir de l’UWpédia par M. David Rouquet. Dans cette ressource, il y a la situation de multivolume dans une même langue. Mais à cause des liens sont mal structurés, nous sommes en trains de manipuler cette ressource pour recalculer les liens. On ferra le passage à l’échelle de cette ressource dans un bref délais.
Références
A single database for all EU-related terminology (InterActiveTerminology for Europe) in 23 languages opens to the public, (2007) Press release. Brussels. 2007-06-28.
Dikonov V., Boguslavsky I., (2009) Semantic Network of the UNL Dictionary of Concepts. Proceedings of the SENSE Workshop on conceptual Structures for Extracting Natural language SEmantics Moscow, Russia, July 2009, 7p.
Diller, G.A., Beckwith, R., Fellbaum, C.,
Gross, D., et Miller, K.J. (1990) Introduction to WordNet:
an on-line lexical database, International Journal of Lexicography 3(4),
pages 235-244.
Dolan, W.B. & Richardson, S.D., (1996) Interactive Lexical Priming for Disambiguation. Proc. MIDDIM'96, Post-COLING seminar on Interactive Disambiguation, C. Boitet ed. Le Col de Porte, Isère, France. 12-14 août 1996. vol. 1/1 : pp. 54-56.
Dong, Z.D., Dong, Q., Hao, C.L., (2010). HowNet and Its Computation of Meaning. In Actes de Coling 2010, Beijing, 4p.
Francopoulo, G., Bel,
N., George, M., Calzolari, N., Monachini,
M., Pet, M. et Soria, C. (2009). Multilingual resources for NLP in the lexical markup
framework (LMF). In journal de Language
Resources and Evaluation,
March 2009, Volume 43, pages 55-57.
Lafourcade, M.,
Joubert, A. (2010). Computing trees
of named word usages from a crowdsourced lexical network.
Investigationes
Linguisticae, vol. XXI, pp. 39-56
Lux-Pogodalla, V., Polguère, A. (2011) Construction of a French Lexical Network: Methodological Issues. Proceedings of the First International Workshop on Lexical Resources, WoLeR 2011. An ESSLLI 2011 Workshop. Ljubljana, 2011. P. 54—61.
Mangeot, M. (2002). An XML Markup Language Framework for Lexical Databases Environments: the Dictionary Markup Language. In Actes de LREC 2002, pages 37-44.
Mangeot, M & Chalvin, A. (2006). Dictionary
Building with the Jibiki Platform : the GDEF case. In
Actes de LREC 2006, Genoa, pages 1666-1669.
Mangeot, M. & Touch, S., (2010) MotÀMot project: building a multilingual
lexical system via bilingual dictionaries.
Proc. SLTU 2010 : Second
International Workshop on Spoken Languages
Technologies for Under-Resourced Languages,
Penang, Malaysia, 2010, 6p.
McCrae, J., Spohr, D.
and Cimiano, P., (2011) Linking lexical resources ans ontologies on the semantic
web with lemon. Proc. ESWC’11, Berlin, pages 245-259.
Nguyen,
H.T., Boitet,
C. et Sérasset, G. (2007). PIVAX, an online
contributive lexical data base for heterogeneous MT systems using a lexical pivot. In
Actes de SNLP-2007, Bangkok, 6 p.
Richardson, S.D., Dolan, W.B. and Vanderwende, L. (1998) MindNet: acquiring and structuring semantic information from text, no. MSR-TR-98-23.
Sérasset, G. (2012) Dbnary: Wiktionary as a LMF based Multilingual RDF network. In Actes de LERC2012, Istanbul, 7p.
Sérasset, G. et Mangeot, M. (2001). Papillon Lexical Database Project: Monolingual Dictionaries and Interlingual Links. In Proc. Of NLPRS 2011, Tokyo, pages 119-125.
Tran, M.
(2006). Prolexbase : Un dictionnaire relationnel
multilingue de noms propres : conception, implémentation et gestion en ligne. Thèse
de doctorat, Tours, pages 54-57.
Vossen, P., (1998) EuroWordNet: A Multilingual Database with Lexical Semantic Networks, Computers and the Humanities, 32(2-3).
Zhang, Y. & Mangeot, M., (2013).
Gestion des terminologies riches : l'exemple des acronyms. In Actes de TALN
2013, Les Sables d’Olonnes, 8 p.